
By the end of this article I want you, the reader, to come away with two very clear reasons as to why every tick matters in crypto market data. One of these reasons highlights the importance of capturing all the relevant data. The other comes from the perspective of using all the relevant data.
But first a digression.
Some of those reading this (not me, of course!), might just be old enough to remember the switch over from analogue music formats to compact discs. At the time there was consternation amongst stereo buffs about the loss of fidelity due to the sampling required to produce a digital version of something that's inherently analogue. As it transpired, this was mainly a storm in a teacup as it quickly became apparent that the average human was not capable of recognising the difference between analogue music and the CD equivalent. (Apart from the loss of the nice, warm, fuzzy clicks and buzzes, of course).
Now you might be thinking "That's all very interesting, and thanks LO, but what does it have to do with your kick-ass market data service?". Quite a bit actually - but bear with me.
Another reminisce, on something closer to topic. When crypto exchanges first got going, you were lucky if you could get any market data from them via an API. Repeatedly pinging Mt. Gox REST endpoints for the latest trades? Yep. Horribly inconsistent top-of-book messages from Poloniex? Yep. A situation worse than awful; it was hard to get information into automated systems, and when you did, you were never 100% sure it could be trusted, or that it was up to date. It was only when Bitfinex (or was it Poloniex?) began to take websockets seriously around 2014-15, with the introduction of streamed order books, that things began to improve.
And order books are particularly important in crypto market data. “Why is that LO?” Well, primarily because crypto can be traded in tiny price and size increments, and exchanges often set up their markets to mirror this. This means the top-of-book often becomes a battleground of tiny price and size updates, with little incremental ‘information’ about the true value of an asset being on display at this level. A trader using top-of-book data alone gets very little actual information about the market’s overall view of the value of the instrument being traded. For that, they need the wider view that’s encompassed by an order book. This makes sense; more information, better valuation.
But order books in crypto are tricky beasts. Unlike TradFi where order book information tends to be delivered via a full Level 3 stream with individual order messages, crypto venues normally deliver order book data in a less verbose combination of (initial) full order book snapshots and subsequent depth updates. The snapshot-plus-depth paradigm has the benefit of limiting the amount of information that clogs up the websockets between venue and client.
But this paradigm comes at a price; the receiving user needs to be capable of building and maintaining an accurate local version of the order book themselves at all times. Importantly, this involves ensuring that absolutely zero depth updates are missed, or dropped, between snapshots. Not a trivial task when dealing with a combination of venues that can randomly disconnect websockets and with message delivery happening across the public internet.
If some depth updates are indeed missed, this can lead to a subtle drift in the state of a user’s order book away from reality, impacting their view of the market and potentially leading to all sorts of nastiness. As some venues do not require a user to re-collect a snapshot (or do not send one out again) this drift can persist almost indefinitely, leaving a user with a persistently incorrect view of the state of the order book. Unlike with the earlier example of CDs, less information here is not tolerable, every message is required for correctness.
Conclusion 1: collecting every tick matters when looking to build order books correctly
(Corollary: if you have a need to build accurate real-time order books for live use, or to store them for later, you better be damn sure you have infrastructure in place to not miss any messages, even when the exchange randomly disconnects one of your websocket connections)
“That’s great LO, but I’m not building order books, I’m using them for research. Surely I can just use data that’s been sampled, say, every 5 seconds, and I’ll be fine?” Of course you can do this, of course you can. If you are confident those order books have been built correctly, then go for it. Or if you want to poll a REST endpoint to get a snapshot, go for it. Many investment and trading strategies operate at frequencies, and with signals, that are much slower. These can live happily on much less granular data. But be aware of what you are losing when you choose this route.
The point I want to make in heading towards the second conclusion, is about the value of information and about using all the possible data that’s available, when you can. Consider the following stylised plot:
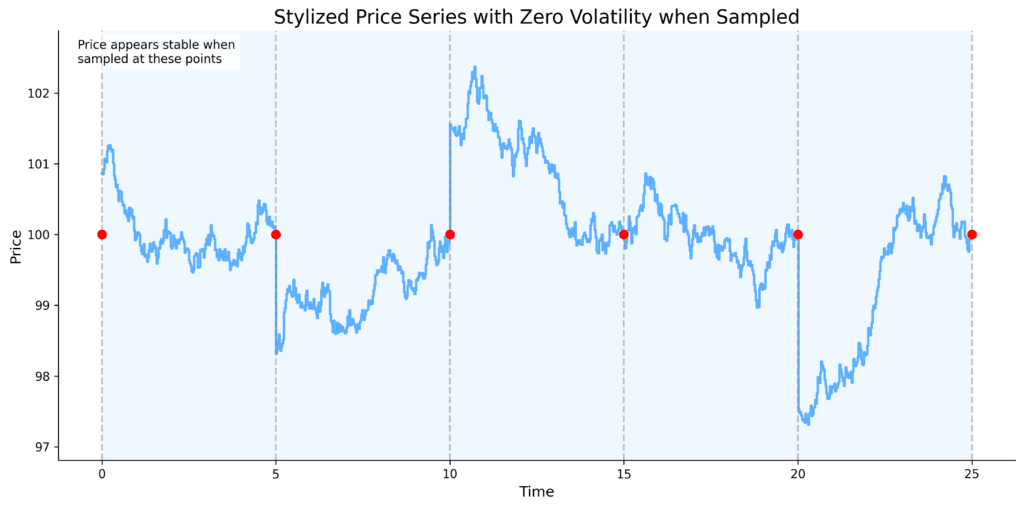
Sampling == lost information. No one would seriously suggest that the series in the plot has zero volatility, but with samples taken at each of the red dots that’s exactly what the calculation will return. Now, of course, this example is artificially constructed, but the underlying point is valid - sampling (or working with less than complete data) can remove vital information, and increase the disparity between calculation results and the reality of the underlying process.
For a trading business like LO:TECH that operates at high frequency, sampling is not an option. Our systems need to be able to react to every single tick from every single market in which we are active. Although not (yet) as crushingly large as TradFi data feeds, this can often mean many hundreds of updates per second. To give you an idea of what I mean, below is a data from a randomly selected 20 minute period looking at the top of book BTC-USDT spot feed from Binance.
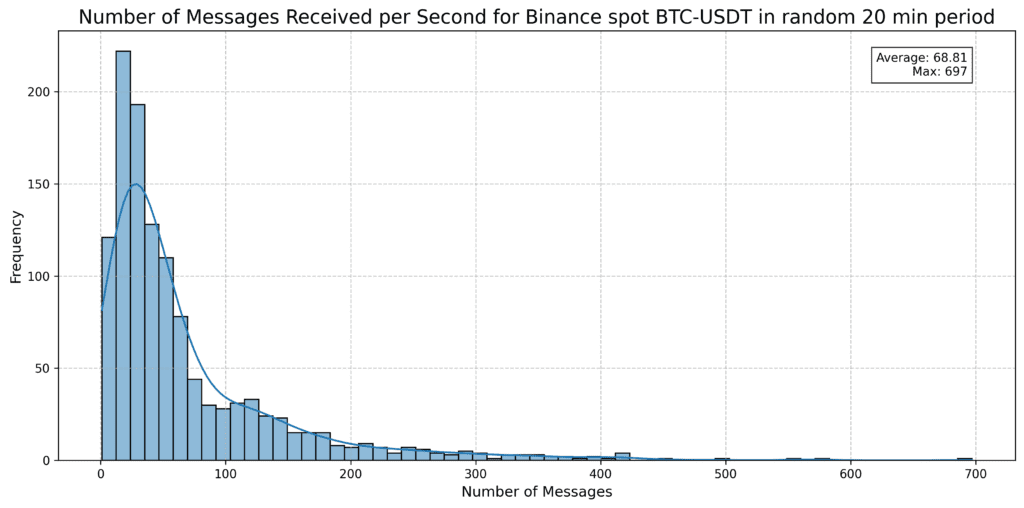
That’s 70-odd messages per second, 70 new pieces of information to be assessed to give our systems a complete picture. And that’s just one of the many feeds consumed (trades, order book updates etc. are also taken in). Each of those new pieces of information could be the one that prompts us to take an action, such as cancelling an order, or amending a quantity. Taking the CD approach of sampling being ‘good enough’ simply wont cut it in this realm - that’s why for our business, and hundreds of others like it, when it comes to market data - every tick matters.
Conclusion 2: working with incomplete information leads to a sub-optimal understanding. When performing research using market data, it pays to have the most granular data possible to give a near-complete a picture of reality.
LO:TECH is proud of the completeness of it’s market data solution. We use this data in our production trading systems and the processes around collecting it, processing it and storing it have been refined over many years of hard work. If you would like to chat us about our data solutions reach out at [email protected]

